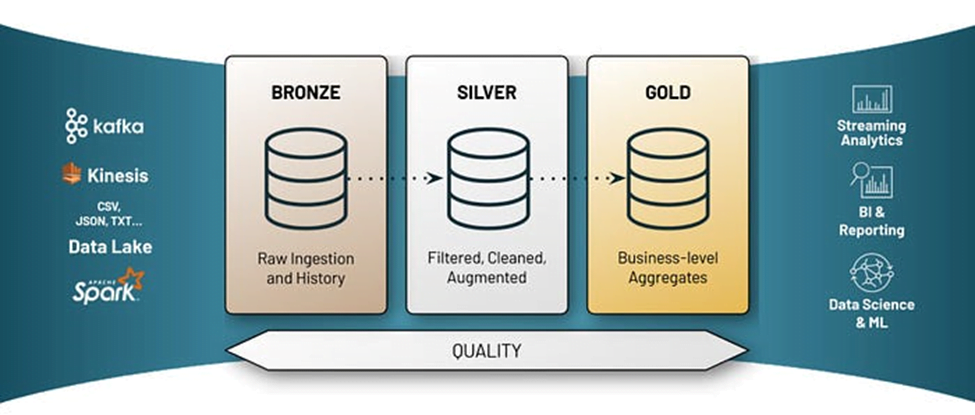
Many organizations
leverage Medallion Architecture to organize data logically within a data
lakehouse. This approach involves processing incoming data through distinct stages,
often called "layers." The most common structure utilizes Bronze,
Silver, and Gold tiers, which is why "Medallion Architecture" is
used.
While the 3-layer design
remains popular, discussions regarding the scope, purpose, and best practices
for each layer are ongoing. Additionally, a gap often exists between
theoretical concepts and real-world implementation. Here's a breakdown of these
data architecture layers with practical considerations:
Data
Platform Strategy: A Foundation for Layering
The initial and crucial
consideration for your data architecture's layering is your data platform's
usage. A centralized and shared platform will likely have a different structure
when compared to a federated, multi-platform setup used by various domains.
Layering can also vary depending on platform alignment source-system alignment or consuming-side alignment. Source-system-aligned platforms are generally easier
to standardize in terms of layering and structure due to the more predictable
data usage on the source side.
Exploring
Each Layer: Theory and Practice
Let's delve into each
layer, outlining its goals and practical observations from real-world
applications.
Landing
Zone (Optional):
Purpose: A temporary storage
location for data gathered from various sources before it's transferred to the
Bronze layer. This layer becomes particularly relevant when extracting data
from challenging source systems, such as those of external clients or SaaS
vendors.
Implementation Considerations:
The design of a landing zone can vary significantly. It's often a simple Blob
storage account, but in some cases, it might be integrated directly with data
lake services like a container, bucket, or designated folder for data
ingestion. The data housed here can be quite diverse, encompassing file formats
like CSV, JSON, XML, Parquet, Delta, and more.

Bronze
Layer: Raw and Un-validated Data
Purpose: A
repository for storing data in its original, un-validated state. It houses
un-validated data (without requiring predefined schemas). Data arrives through
full loads or delta loads.
Key characteristics include:
o Maintains
the raw state of the data source in the structure “as-is”.
o Data
is immutable (read-only).
o Managed
using interval partitioned tables, for example, using a YYYYMMDD or date-time
folder structure.
o Retains
the full (unprocessed) history of each dataset in an efficient storage format,
for example, Parquet or Delta.
o For
transactional data: This can be appended incrementally and grow over time.
o Provides
the ability to recreate any state of a given data system.
o Can
be any combination of streaming and batch transactions.
o May
include extra metadata, such as schema information, source file names, or
recording the time data was processed.
A common query I encounter is, “Which
file format is superior? Should I opt for Delta or Parquet?” While Delta offers
faster speed, its benefits aren’t as pronounced if your data is already
versioned or historised using a folder structure. As such, maintaining a
transaction log or applying versioning isn’t crucial. Bronze data is typically
new or appended data. Therefore, selecting Parquet is perfectly acceptable.
However, you could also choose Delta to remain consistent with other layers.
For
transactional data: This can be appended incrementally
and grow over time.
o Provides
the ability to recreate any state of a given data system.
o Can
be a combination of streaming and batch transactions.
o May
include additional metadata, such as schema information, source file names, or
data processing timestamps.
Format
Selection: While Delta offers faster speeds, its
benefits are less pronounced if your data is already versioned or historiated
using a folder structure. In such cases, maintaining a transaction log or
applying versioning isn't essential. Parquet is perfectly acceptable for Bronze
data. However, Delta can be chosen for consistency across layers.
Business
User Access: It's uncommon for raw data in the Bronze
layer to be directly used for business user queries or ad-hoc analyses due to
its complexity and lack of inherent structure. Securing this layer with
numerous small tables can also be challenging. Therefore, Bronze serves
primarily as a staging layer and a source for other layers, accessed mainly by
technical accounts.
Beyond Parquet and Delta:
Exploring Apache Iceberg
Parquet
and Delta Lake are popular data storage options for Medallion Architecture.
While these are excellent choices, Apache Iceberg is emerging as a strong
contender.
Here's why you might consider it:
o Scalability: Iceberg
excels at handling massive datasets efficiently, making it ideal for
large-scale data lakes.
o ACID Compliance: It
offers ACID (Atomicity, Consistency, Isolation, Durability) guarantees,
ensuring data integrity in concurrent write operations.
o Schema Evolution: Iceberg
gracefully handles schema changes, allowing you to evolve your data model over
time without compromising data integrity.
Silver
Layer: Refined and Enriched Data
Purpose:
Provides a refined structure over ingested data. It represents a validated,
enriched version of the data that can be trusted for downstream operational and
analytical workloads.
Key characteristics include:
o It utilizes data quality rules for data
validation and processing.
o It typically contains only functional data,
so technical or irrelevant data from Bronze is filtered out.
o Historization is usually applied by merging
all data. Data is processed using slowly changing dimensions (SCD), either type
2 or type 4. This involves adding additional columns, such as start, end, and
current columns.
o Data
is stored in an efficient storage format; preferably Delta, alternatively
Parquet.
o Uses
versioning for rolling back processing errors.
o Handles
missing data and standardizes clean or empty fields.
o Data
is usually enriched with reference and/or master data.
o Data
is often clustered around specific subject areas.
o Data
may still be source-system aligned and organized, meaning it has not been
integrated with data from other domains yet.
Considerations
for Silver as a Transient Layer:
Some
propose Silver as a transient storage layer, enabling the deletion of outdated
data or the spontaneous creation of storage accounts. The decision depends on
your needs. If you don't plan to use data in its original context for
operational reporting or analytics, then Silver can be temporary.
However,
if you require historical data for operational reporting and analytics,
establish Silver as a permanent layer.
Silver
Layer Design Optimization:
Denormalized
Data Model: When querying Silver data, consider using
a denormalized data model. This approach eliminates the need for extensive
joins and aligns better with the distributed columnar storage architecture.
However, there's no need to abandon established data modeling practices like
the 3rd normal form or Data Vault if they suit your needs.
Regarding historicization, the Delta file format
already versions Parquet files, and you have a historical record in your Bronze
layer for reloading data if necessary. For automation and adaptability, a
metadata-driven strategy is recommended for managing tables and notebooks. Data
redundancy in a lake environment is less expensive than the computational
processing and data joining required to eliminate it. Unless you're dealing
with significant daily schema changes, the complexity of a data vault might not
be necessary.
Silver
Layer Integration Considerations:
Data
Integration: The question of whether to integrate data
between applications and source systems in the Silver layer arises frequently.
For easier management and isolation of concerns, it's generally recommended to
keep things separate if possible. This suggests that if you're using Silver for
operational reporting or analytics, avoid prematurely merging and integrating
data from source systems. Doing so could lead to unnecessary connection points
between applications. Users interested only in data from a single source might
be linked to other systems if the data is first combined in a harmonized layer
before being provided.
Consequently, these data
users are more likely to experience potential impacts from other systems. If
you're striving for an isolated design, the integration or combination of data
from different sources should be moved up to the Gold layer. The same reasoning
applies to aligning your Lakehouses with the source-system side of your
architecture. If you plan to build data products and are particular about data
ownership, then advise against engineers prematurely cross-joining data from
applications in other domains.
Data
Enrichment: When considering enrichments like calculations
in the Silver layer, your goal plays a key role. If operational reporting
requires enrichments, you can start enriching data in Silver. This might lead
to some additional calibration when merging data later in the Gold stage. While
this may require additional effort, the flexibility it offers can be
worthwhile.
Gold
Layer: Project-Specific, Integrated Data
Purpose:
The Gold layer houses data structured in "project-specific"
databases, readily available for consumption. This integration of data from various
sources may result in a shift in data ownership. Key characteristics of the
Gold layer include:
o Gold tables represent data transformed for
consumption or specific use cases.
o Data is stored in an efficient storage
format, preferably Delta.
o Gold uses versioning for rolling back
processing errors.
o Historization is applied only for the
relevant use cases or consumers. So, Gold can be a selection or aggregation of
data found in Silver.
o Complex business rules are applied in Gold.
It utilizes post-processing activities, calculations, enrichments, and
use-case-specific optimizations.
o Data is highly governed and
well-documented.
Bronze
Layer: Raw and Un-validated Data
Purpose: A
repository for storing data in its original, un-validated state. It houses
un-validated data (without requiring predefined schemas). Data arrives through
full loads or delta loads.
Key characteristics include:
o Maintains
the raw state of the data source in the structure “as-is”.
o Data
is immutable (read-only).
o Managed
using interval partitioned tables, for example, using a YYYYMMDD or date-time
folder structure.
o Retains
the full (unprocessed) history of each dataset in an efficient storage format,
for example, Parquet or Delta.
o For
transactional data: This can be appended incrementally and grow over time.
o Provides
the ability to recreate any state of a given data system.
o Can
be any combination of streaming and batch transactions.
o May
include extra metadata, such as schema information, source file names, or
recording the time data was processed.
A common query I encounter is, “Which
file format is superior? Should I opt for Delta or Parquet?” While Delta offers
faster speed, its benefits aren’t as pronounced if your data is already
versioned or historised using a folder structure. As such, maintaining a
transaction log or applying versioning isn’t crucial. Bronze data is typically
new or appended data. Therefore, selecting Parquet is perfectly acceptable.
However, you could also choose Delta to remain consistent with other layers.
For
transactional data: This can be appended incrementally
and grow over time.
o Provides
the ability to recreate any state of a given data system.
o Can
be a combination of streaming and batch transactions.
o May
include additional metadata, such as schema information, source file names, or
data processing timestamps.
Format
Selection: While Delta offers faster speeds, its
benefits are less pronounced if your data is already versioned or historiated
using a folder structure. In such cases, maintaining a transaction log or
applying versioning isn't essential. Parquet is perfectly acceptable for Bronze
data. However, Delta can be chosen for consistency across layers.
Business
User Access: It's uncommon for raw data in the Bronze
layer to be directly used for business user queries or ad-hoc analyses due to
its complexity and lack of inherent structure. Securing this layer with
numerous small tables can also be challenging. Therefore, Bronze serves
primarily as a staging layer and a source for other layers, accessed mainly by
technical accounts.
Beyond Parquet and Delta:
Exploring Apache Iceberg
Parquet
and Delta Lake are popular data storage options for Medallion Architecture.
While these are excellent choices, Apache Iceberg is emerging as a strong
contender.
Here's why you might consider it:
o Scalability: Iceberg
excels at handling massive datasets efficiently, making it ideal for
large-scale data lakes.
o ACID Compliance: It
offers ACID (Atomicity, Consistency, Isolation, Durability) guarantees,
ensuring data integrity in concurrent write operations.
o Schema Evolution: Iceberg
gracefully handles schema changes, allowing you to evolve your data model over
time without compromising data integrity.
Silver
Layer: Refined and Enriched Data
Purpose:
Provides a refined structure over ingested data. It represents a validated,
enriched version of the data that can be trusted for downstream operational and
analytical workloads.
Key characteristics include:
o It utilizes data quality rules for data
validation and processing.
o It typically contains only functional data,
so technical or irrelevant data from Bronze is filtered out.
o Historization is usually applied by merging
all data. Data is processed using slowly changing dimensions (SCD), either type
2 or type 4. This involves adding additional columns, such as start, end, and
current columns.
o Data
is stored in an efficient storage format; preferably Delta, alternatively
Parquet.
o Uses
versioning for rolling back processing errors.
o Handles
missing data and standardizes clean or empty fields.
o Data
is usually enriched with reference and/or master data.
o Data
is often clustered around specific subject areas.
o Data may still be source-system aligned and organized, meaning it has not been integrated with data from other domains yet.
Considerations
for Silver as a Transient Layer:
Some
propose Silver as a transient storage layer, enabling the deletion of outdated
data or the spontaneous creation of storage accounts. The decision depends on
your needs. If you don't plan to use data in its original context for
operational reporting or analytics, then Silver can be temporary.
However,
if you require historical data for operational reporting and analytics,
establish Silver as a permanent layer.
Silver
Layer Design Optimization:
De-normalized
Data Model: When querying Silver data, consider using
a de-normalized data model. This approach eliminates the need for extensive
joins and aligns better with the distributed columnar storage architecture.
However, there's no need to abandon established data modeling practices like
the 3rd normal form or Data Vault if they suit your needs.
Regarding historicization, the Delta file format
already versions Parquet files, and you have a historical record in your Bronze
layer for reloading data if necessary. For automation and adaptability, a
metadata-driven strategy is recommended for managing tables and notebooks. Data
redundancy in a lake environment is less expensive than the computational
processing and data joining required to eliminate it. Unless you're dealing
with significant daily schema changes, the complexity of a data vault might not
be necessary.
Silver
Layer Integration Considerations:
Data
Integration: The question of whether to integrate data
between applications and source systems in the Silver layer arises frequently.
For easier management and isolation of concerns, it's generally recommended to
keep things separate if possible. This suggests that if you're using Silver for
operational reporting or analytics, avoid prematurely merging and integrating
data from source systems. Doing so could lead to unnecessary connection points
between applications. Users interested only in data from a single source might
be linked to other systems if the data is first combined in a harmonized layer
before being provided.
Consequently, these data
users are more likely to experience potential impacts from other systems. If
you're striving for an isolated design, the integration or combination of data
from different sources should be moved up to the Gold layer. The same reasoning
applies to aligning your Lakehouses with the source-system side of your
architecture. If you plan to build data products and are particular about data
ownership, then advise against engineers prematurely cross-joining data from
applications in other domains.
Data
Enrichment: When considering enrichments like calculations
in the Silver layer, your goal plays a key role. If operational reporting
requires enrichments, you can start enriching data in Silver. This might lead
to some additional calibration when merging data later in the Gold stage. While
this may require additional effort, the flexibility it offers can be
worthwhile.
Gold
Layer: Project-Specific, Integrated Data
Purpose:
The Gold layer houses data structured in "project-specific"
databases, readily available for consumption. This integration of data from various
sources may result in a shift in data ownership. Key characteristics of the
Gold layer include:
o Gold tables represent data transformed for
consumption or specific use cases.
o Data is stored in an efficient storage
format, preferably Delta.
o Gold uses versioning for rolling back
processing errors.
o Historization is applied only for the
relevant use cases or consumers. So, Gold can be a selection or aggregation of
data found in Silver.
o Complex business rules are applied in Gold.
It utilizes post-processing activities, calculations, enrichments, and
use-case-specific optimizations.
o Data is highly governed and
well-documented.

Gold
Layer Complexity: The Gold layer is often the most intricate
layer due to its design being dependent on the overall architecture's scope. In
a basic setup where your Lakehouses are solely source-system aligned, data in
the Gold layer represents "data product" data, making it general and
user-friendly for distribution to numerous domains. Following this
distribution, the data is expected to be housed in another platform, possibly
another Lakehouse.
Gold
Layer Variations Based on Architecture Scope
Depending on the breadth
of your architecture, your Gold layer could be a combination of data product
data and use-case-specific data. In such scenarios, the Gold Layer in these
platforms caters to the exact needs of analytic consumers. The data is modeled
with a shape and structure tailored specifically for the use case in progress.
This method fosters principles where you only allow domains to function on
internal data that isn't directly distributed to other domains. Therefore, some
tables may be flexible and adjustable, while other tables with a formal status
are consumed by other entities.
For broader Lakehouse
architectures encompassing both provider and consumer ends, anticipate
additional layers, often referred to as workspace or presentation layers. In
this configuration, the data in Gold is more universal, integrated, and ready
for various use cases. These workspace or presentation layers then contain
subsets of data, resembling traditional data modeling within data warehousing.
Essentially, Gold serves as a universal integration layer from which data marts
or subsets can be filled.
Gold
Layer for Data Dissemination and Governance:
Certain organizations
utilize workspace or presentation layers to disseminate data to other platforms
or teams. They achieve this by selecting and/or pre-filtering data for specific
scenarios. Some organizations implement tokenization, which involves substituting
sensitive data with randomized strings. Others employ additional services for
data anonymization. This data can be seen as behaving similarly to "data
product" data.
The Gold layer often
stands out for its adherence to enterprise-wide standards. While enterprise
data modeling can be complex and time-consuming, many organizations still
utilize it to ensure data reusability and standardization. Here are some
approaches to consider for achieving standardization in the Gold layer:
Enterprise
Data Model: The enterprise data model provides an
abstract framework for organizing data within teams' Lakehouses. The enterprise
model typically outlines specific data elements and requires teams to follow
specific reference values or include master identifiers when sharing datasets
with other teams.
Centralized
Data Harmonization: An alternative approach involves
gathering, harmonizing, and distributing data in a separate Lakehouse
architecture. From there, data can be consumed downstream by other domains,
similar to a master data management approach.
Domain-Specific
Ownership: Another option is to mandate teams to take
responsibility for specific harmonized entities. Other teams must then conform
by consistently using these entities.
In most cases,
standardization and harmonization primarily occur within the Gold layer.

Technology
Considerations for the Gold Layer
Choosing a database or
service for the Gold layer is a complex decision. It requires careful
consideration of various factors and involves making compromises. Beyond data
structure, you'll need to assess your requirements in terms of:
- Consistency:
How strictly does your data need to be consistent across reads?
- Availability:
How crucial is it for your data to be constantly accessible?
- Caching:
Can caching strategies improve query performance?
- Timeliness:
How quickly do you need data updates to reflect in the Gold layer?
- Indexing:
How can indexing strategies optimize specific queries?
There is no single service
that excels in all of these aspects simultaneously. A typical Lakehouse
architecture often comprises a blend of diverse technology services, such as:
- Server-less
SQL services for ad-hoc queries.
- Columnar
stores for fast reporting.
- Relational
databases for more complex queries.
- Time-series
stores for IoT and stream analysis.
By understanding the
theoretical foundations and practical considerations of each layer, you can
effectively implement Medallion Architecture for your data lakehouse. Remember,
the "best practices" can vary depending on your specific data
platform strategy and the overall scope of your Lakehouse architecture. Choose
the approaches and technologies that best align with your unique needs and
goals for optimal data management.

Dot Labs is an IT
outsourcing firm that offers a range of services, including software
development, quality assurance, and data analytics. With a team of skilled
professionals, Dot Labs offers nearshoring services to companies in North
America, providing cost savings while ensuring effective communication and
collaboration. Visit our website: www.dotlabs.ai, for more information on how Dot
Labs can help your business with its IT outsourcing needs. For more informative
Blogs on the latest technologies and trends click
here


