
In today's data-driven world, the ability to harness the power of data is more critical than ever. Businesses rely on sophisticated data strategies to gain insights, drive decision-making, and maintain a competitive edge. A pivotal component of modern data strategies is Cloud-Native Data Engineering. This approach leverages the power of cloud computing to manage, process, and analyze data efficiently and effectively. In this blog, we will delve into the main aspects of Cloud-Native Data Engineering, exploring its benefits, challenges, and best practices.
Understanding Cloud-Native Data Engineering
Cloud-Native Data Engineering refers to designing and building data systems and architectures that fully leverage the cloud's inherent scalability, flexibility, and resilience. Unlike traditional on-premises data solutions, cloud-native approaches utilize cloud services and infrastructure to enhance data processing capabilities. These principles define our approach:
Scalability: Cloud-native data systems can scale seamlessly to handle large volumes of data, ensuring that businesses can process and analyze data in real time.
Flexibility: With cloud-native solutions, businesses can choose the tools and services, customizing their data architecture to meet specific needs.
Cost-Effectiveness: By leveraging pay-as-you-go pricing models, companies can optimize costs and allocate resources more efficiently.
Resilience: Cloud-native systems are to be super reliable and resilient, keeping downtime to a minimum and safeguarding your data at all times.
Benefits of Cloud-Native Data Engineering
Enhanced Performance and Speed: Cloud-native data engineering enables businesses to process large datasets quickly. By utilizing distributed computing and parallel processing, data engineers can supercharge performance and drastically memorize waiting times. It is particularly beneficial for real-time analytics, as quick insights are crucial.
Improved Data Integration: Integrating data from various sources is a common challenge for businesses. Cloud-native data engineering solutions offer advanced integration capabilities, allowing seamless data ingestion from multiple sources, including databases, APIs, and streaming platforms. This integration ensures a holistic view of the business, facilitating better decision-making.
Cost Optimization: Traditional data systems often require significant upfront investments in hardware and software. In contrast, cloud-native solutions operate on a pay-as-you-go model, allowing businesses to scale resources up or down based on demand. This flexibility not only reduces costs but also optimizes resource allocation.
Enhanced Security: Security is a paramount concern for any data strategy. Cloud providers offer robust security measures, including encryption, access controls, and compliance certifications. By leveraging these security features, businesses can protect their data from breaches and ensure regulatory compliance.
Simplified Management: Managing on-premises data infrastructure can be complex and resource-intensive. Cloud-native data engineering simplifies management through automated scaling, monitoring, and maintenance, which allows data engineers to focus on strategic initiatives rather than routine operational tasks.
Key Components of Cloud-Native Data Engineering
Data Ingestion: Data ingestion collects and imports data from various sources into a central repository. To create a cloud-native environment, it's essential to utilize services such as AWS Glue, Azure Data Factory, or Google Cloud Dataflow to optimize the ingestion process. These powerful tools come with pre-built connectors and ETL (Extract, Transform, Load) capabilities, which allow for the smooth integration of data across different platforms.
Data Storage: Cloud-native data storage solutions, such as Amazon S3, Azure Blob Storage, and Google Cloud Storage, provide scalable and cost-effective options for storing vast amounts of data. These storage handle structured, semi-structured, and unstructured data, ensuring flexibility in data management.
Data Processing: Processing large datasets requires robust computing power. Cloud-native data engineering leverages services like AWS Lambda, Azure Functions, and Google Cloud Functions for serverless computing. These services allow data engineers to run code in reply to events, enabling real-time data processing without dedicated servers.
Data Analytics: Analytics is a critical component of any data strategy. Cloud-native solutions offer powerful analytics tools like Amazon Redshift, Azure Synapse Analytics, and Google BigQuery. These services provide scalable data warehousing and advanced analytics capabilities, allowing businesses to derive actionable insights from their data.
Data Visualization: Effective data visualization helps communicate insights. Cloud-native tools like Amazon QuickSight, Microsoft Power BI, and Google Data Studio offer intuitive interfaces and interactive dashboards. These tools enable businesses to create compelling visualizations and share insights across the organization.
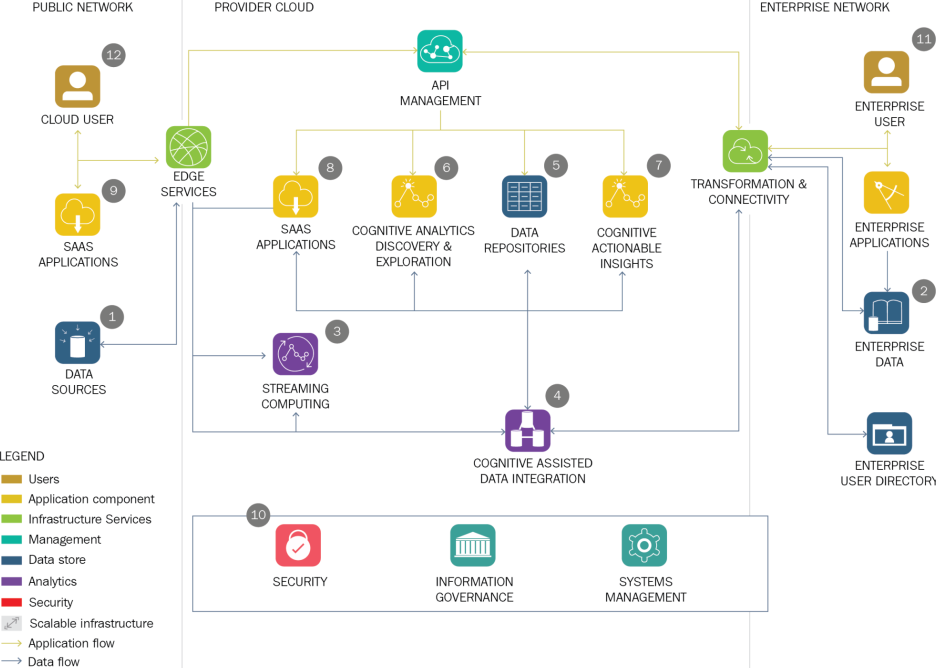
Cloud-Native Architecture
Best Practices for Implementing Cloud-Native Data Engineering
Embrace a Microservices Architecture: A microservices architecture breaks down applications into independent services. This approach enhances flexibility and scalability, allowing businesses to deploy and update individual components without affecting the entire system. In cloud-native data engineering, microservices enable modular data processing and integration.
Adopt a DevOps Culture: DevOps practices promote collaboration between development and operations teams, ensuring continuous integration and delivery. By adopting a DevOps culture, businesses can streamline the deployment of cloud-native data solutions, reduce time-to-market, and improve overall efficiency.
Implement Data Governance: Data governance involves establishing policies and procedures to manage data quality, security, and compliance. In a cloud-native environment, data governance is crucial to ensure data integrity and regulatory compliance. Implementing data governance frameworks and tools helps in maintaining data accuracy and reliability.
Leverage Automation: Automation plays a vital role in cloud-native data engineering. Automated workflows, such as data pipeline orchestration and infrastructure provisioning, reduce manual intervention and minimize errors. Tools like Apache Airflow, AWS Step Functions, and Azure Logic Apps enable automation, enhancing operational efficiency.
Monitor and Optimize Performance: Continuous monitoring and optimization are essential for maintaining the performance of cloud-native data systems. Implementing monitoring tools like AWS CloudWatch, Azure Monitor, and Google Cloud Operations Suite allows businesses to track key metrics, identify bottlenecks, and optimize real-time performance.
Challenges and Solutions in Cloud-Native Data Engineering
Data Security and Privacy: While cloud providers offer robust security measures, ensuring data security and privacy remains challenging. Businesses must implement additional security layers, such as encryption, identity, access management (IAM), and network security to protect sensitive data.
Skill Gap: Adopting cloud-native data engineering requires specialized skills and expertise. Businesses should invest in training and development programs to upskill their teams. Partnering with cloud service providers and consulting firms can also bridge the skill gap and ensure successful implementation.
Cost Management: While cloud-native solutions offer cost advantages, managing cloud costs can be challenging. Businesses must implement cost management practices, such as monitoring usage, setting budgets, and optimizing resource allocation to control expenses effectively.
Data Integration Complexity: Integrating data from diverse sources can be complex and time-consuming. Leveraging cloud-native integration tools and adopting standardized data formats can simplify the integration process. Additionally, using data catalogs and metadata management solutions can enhance data discoverability and integration.
Regulatory Compliance: Compliance with data protection regulations such as GDPR and CCPA is critical for businesses handling sensitive data. Implementing compliance frameworks, conducting regular audits, and maintaining transparent data practices can help ensure regulatory compliance in a cloud-native environment.
Future Trends in Cloud-Native Data Engineering
AI and Machine Learning Integration: Combining cloud-native data engineering with artificial intelligence (AI) and machine learning (ML) leads to a remarkable shift in data strategies. Cloud providers offer AI/ML services, such as AWS SageMaker, Azure ML, and Google AI Platform, enabling businesses to build and deploy advanced models for predictive analytics and automation.
Serverless Architectures: Serverless architectures are gaining traction in cloud-native data engineering. By abstracting infrastructure management, serverless computing allows businesses to focus on code and application logic. This approach enhances agility and reduces operational overhead.
Edge Computing: Edge computing brings data processing closer to the source of data generation, reducing latency and bandwidth usage. Integrating edge computing with cloud-native data engineering enables real-time analytics and decision-making in scenarios like IoT and autonomous systems.
DataOps: DataOps is an emerging discipline that applies DevOps principles to data management. By promoting collaboration, automation, and continuous improvement, DataOps enhances the efficiency and quality of data engineering processes. Implementing DataOps practices can streamline data workflows and improve overall performance.
Multi-Cloud Strategies: Businesses are increasingly adopting multi-cloud strategies to leverage the strengths of different cloud providers. This approach enhances resilience, avoids vendor lock-in, and optimizes costs. Implementing multi-cloud data engineering solutions requires robust integration and orchestration capabilities.
Conclusion
Cloud-Native Data Engineering is revolutionizing the way businesses manage and utilize data. By leveraging the scalability, flexibility, and resilience of cloud computing, companies can enhance their data strategies and gain a competitive edge. Implementing best practices, addressing challenges, and staying abreast of emerging trends are crucial for successful cloud-native data engineering. As businesses continue to navigate the data-driven landscape, adopting a cloud-native approach will be the key to unlocking the full potential of their data.

Dot Labs is a leading IT outsourcing firm renowned for its comprehensive services, including cutting-edge software development, meticulous quality assurance, and insightful data analytics. Our team of skilled professionals delivers exceptional nearshoring solutions to companies worldwide, ensuring significant cost savings while maintaining seamless communication and collaboration. Discover the Dot Labs advantage today!
Visit our website: www.dotlabs.ai, for more information on how Dot Labs can help your business with its IT outsourcing needs.
For more informative Blogs on the latest technologies and trends click here


