
In this data-driven world, machine learning (ML) has become a cornerstone for businesses aiming to harness actionable insights from massive data sets. However, the success of ML models often depends on the robustness of the underlying data engineering strategies. Building scalable machine learning pipelines is critical to ensuring efficiency, reliability, and accuracy in AI solutions.
Understanding Machine Learning Pipelines
Data engineering is designing, building, and maintaining data infrastructure. It involves tasks such as data ingestion, cleaning, transformation, storage, and data integration. For ML pipelines, data engineering is essential for the following reasons:
Data Quality: Ensuring data accuracy, completeness, and consistency is crucial for training accurate ML models. Data engineering techniques help identify and rectify data quality issues.
Data Scalability: As data volumes grow exponentially, ML pipelines must be able to handle increasing workloads. Data engineering practices enable the efficient processing and storage of large datasets.
Data Accessibility: Ensuring data is easily accessible to ML practitioners is essential for rapid experimentation and model development. Data engineering facilitates data access through APIs, warehouses, and data lakes.
Data Security and Privacy: Protecting sensitive data is paramount. Data engineering solutions implement robust security measures to safeguard data privacy and compliance with regulations.
Data Engineering Strategies for Scalability
Here are the core strategies to ensure your ML pipelines are scalable and efficient:
Adopt Distributed Data Processing Frameworks
Distributed frameworks like Apache Spark and Hadoop allow you to process massive datasets efficiently. These frameworks enable parallel processing, significantly reducing time-to-insight for ML models.
Leverage Cloud-Native Solutions
Cloud platforms such as AWS, Azure, and Google Cloud offer on-demand scalability for storage and computation. AWS Glue and Google BigQuery focus on managing large-scale data engineering tasks.
Build Modular Pipelines
Modularity ensures that different stages of your pipeline—data ingestion, transformation, and model training—can be scaled independently. Tools like Apache Airflow and Prefect facilitate modular pipeline orchestration.
Ensure Data Quality at Scale
Implementing data quality frameworks like Great Expectations ensures that data issues are automatically detected and corrected. High-quality data leads to better model performance.
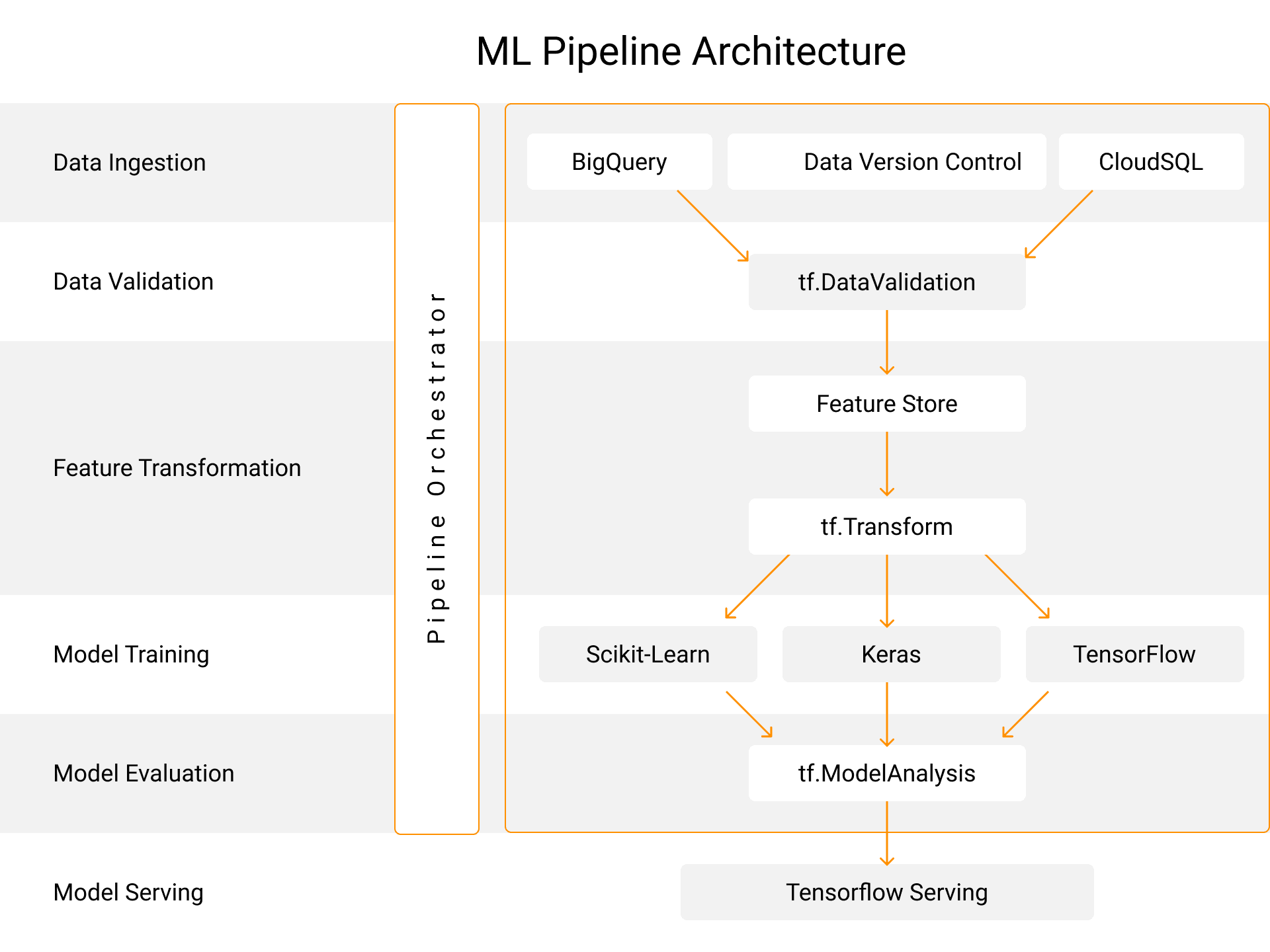
Tools and Technologies for Scalable Pipelines
The choice of tools impacts scalability. Here are some of the most effective ones:
Apache Kafka: For real-time data streaming.
Snowflake: A scalable data warehouse solution.
TensorFlow Extended (TFX): For building production-grade ML pipelines.
Databricks: A unified analytics platform that supports big data and AI.
Key Challenges in Scaling Machine Learning Pipelines
Scaling ML pipelines isn’t just about adding more resources. It involves addressing critical challenges, including:
Data Volume: The growing datasets can overwhelm storage and processing systems.
Processing Speed: Real-time applications demand swift data ingestion and processing.
Pipeline Maintenance: Managing change to data sources, models, and infrastructure is a continuous task.
Monitoring and Optimization for Long-Term Success
Even the most well-designed pipelines need constant monitoring and optimization. Implement observability tools like Prometheus and Grafana to track performance metrics. Regularly evaluate pipeline bottlenecks and update models to reflect changing business requirements.
Best Practices for Scalable Machine Learning Pipelines
To ensure long-term scalability and success:
Automate Repetitive Tasks: Use automation tools to reduce manual intervention.
Focus on Reusability: Design pipelines with reusable components to save development time.
Embrace Version Control: Track changes in data, models, and codebases for reproducibility.
Adopt MLOps Principles: Integrate machine learning operations to streamline collaboration between data engineers and scientists.
Conclusion
Scalable machine learning pipelines are the backbone of successful AI-driven businesses. By implementing robust data engineering strategies, leveraging the right tools, and embracing best practices; organizations can ensure their ML initiatives remain impactful and efficient as data complexity grows.
Building and maintaining these pipelines might seem daunting, but with a systematic approach, you can overcome challenges and unlock new opportunities. Now is the time to optimize your ML pipelines for scalability—because the future of data is bigger than ever.

Dot Labs is a leading IT outsourcing firm renowned for its comprehensive services, including cutting-edge software development, meticulous quality assurance, and insightful data analytics. Our team of skilled professionals delivers exceptional nearshoring solutions to companies worldwide, ensuring significant cost savings while maintaining seamless communication and collaboration. Discover the Dot Labs advantage today!
Visit our website: www.dotlabs.ai, for more information on how Dot Labs can help your business with its IT outsourcing needs.
For more informative Blogs on the latest technologies and trends click here


